|
Paras Aggarwal ManavRachna University Sector - 43, Faridabad, Haryana |
Chetan Singh ManavRachna University Sector - 43, Faridabad, Haryana |
Vinay Kumar Jain ManavRachna University Sector - 43, Faridabad, Haryana |
Gunjan Chandwani ManavRachna University Sector - 43, Faridabad, Haryana |
In this document we'll be giving a brief review on how the recommended system works and the way it's helpful. There square measure numerous styles of basic systems, together with cooperative, content-based, and knowledge-based systems however we tend to commonly specialize in recommended system – content primarily based during which user will get suggested things via ratings or by the interest of the user. Reviews and rating square measure useful for increasing the market rates relating to the merchandise
As the increasing importance in cyber web structure as a middle of electronic as well as business bits of business has given out as a propulsion of the event for recommended system technique. Actually, necessary catalyst during this technique is that the easiness with that net allows users to allow feedback, like and dislikes. this is often terribly simple as on a click we are able to disclose a feedback relating to product. It may well be in any type whether or not in ratings (i.e., stars), comments, like or dislike. Basically, plan of recommended system is to utilize numerous supplies of information to infer client interests. Recommendation analysis is could also be supported the previous interaction between users and merchandise, as a result of history of the merchandise searched by the user square measure usually sensible indicators of future selections or things. So, the essential principle of recommended system is that significance of mutual interaction between user and item/product. In content primarily based suggested system the content plays a main role during this method, during which the ratings provided by the users and also the attribute descriptions of the things square measure leveraged so as to form predictions. The prediction relating to user interest may well be sculptor on the idea of the things they need rated or accessed within the past.
The basic models for suggested systems work on 2 styles of knowledge that are: The user – item interaction, (ratings or shopping for behaviour)The attribute info concerning the user and things, (textual profiles or relevant keywords) Methods that use the previous square measure brought up as cooperative filtering ways, whereas ways that use the latter square measure brought up as content – primarily based recommender ways.Content – primarily based systems may use rating criteria, though the model is sometimes centred on the ratings of one user instead of those of all users. Few of the recommender systems mix completely divergent aspects to form mixed systems. Whereas, combining completely different aspects it will mix the strengths of varied styles of recommender systems to form techniques that may work additional healthily in a very broad range of settings. Collaborative technique uses the cooperative strength of the ratings that many users offer to the merchandise, and these ratings square measure want to create recommendations. for instance: moving picture application during which usersshow their interest by rating as like or dislike of a particular movies. many users have watched a little a part of the big universe of obtainable movies. The terms “specified” associated “observed” are utilized in an interchangeable means. The one rating are marked as “unobserved” or “missing”. Memory primarily based cooperative filtering algorithms square measure valued for his or her simplicity, they are inclined to be heuristic in nature, and that they don't perform well in all told settings. consistent with recent knowledge, memory primarily based and model-based ways give terribly correct results.
Commonly recommendation algorithms square measure influenced by the system that uses ratings for pursuit. Ratings is such, on a range that signifies the particular stage of 'like' or 'dislike' of the merchandise at hand. Ratings is doable at continuous values as like between the vary of -10 to 10. Usually, ratings square measure period-based. for instance, a 5-star rating pointer scale could be drawn from the set [1,2,3,4,5], during which a rating of 1 signifies associate very dislike, after that a rating of two signifies a robust natural liking for the particular item. different systems would possibly use the criteria of rating of [-2, 1,0,1,2]. the amount of doable scaling is varied from system to system. for instance: Netflix also take advantage of 5-star classification system during which,3-star purpose denotes “It had been ok” and the5-star rating purpose is to denote “I really like it”. Hence, here square measure 3 in favor and solely 2 in against ratings in Netflix, that ends up in associate unbalanced rating scale.

Another way to reason may be done as [very disagree, keywords of different fantasy movies like predator and Disagree, Normal, Agree, Very Agree] so as to attain a alien. similar goal
this kind of suggested system, the descriptive attributes modelling drawback. for every buyer, the coaching report of things square measure want to create recommendations. is place up from the descriptions of the things that a user The term “content” refers to the descriptions. during this rated or bought. the category fickle corresponds to the technique, the reviews and ratings from the user's square particular scaling or shopping for behaviour. These measure combined with the content info obtainable within coaching reports square measure want to produce a the merchandise. for instance: suppose someone john rated regression model or classification model, that is restricted a moving picture eradicator extremely, however we tend to to the buyer end. This type of model is introduced to check don't use the scaling of another users. Here, cooperative whether or not the user can like associate product that filtering ways square measure dominated out. whereas, the he/she rated or shopping for behaviour is unknown. things detail of eradicator consists ofsame kind of genre
path doesn't use the user's ratings within the recommendation method, and it's so helpful in cold-start eventualities.Content primarily based recommendation ways have some benefits for creating recommendations for brand new things, once applicable rating knowledge aren't obtainable for that item. It may well be of the explanation that different things with similar attribute would possibly been scaled by the operatinguser. Hence, the supervised technique is ready to leverage these scaling in association with the product attributes to form recommendations to once when there's no history of rating that item.
Content primarily based recommended systems try and match keywords that square measure the same as what they need liked within the past. Similarity isn't in and of itself essentially supported rating links across buyers however on the idea of the attributes of the objects that square measure that users liked. not like cooperative systems, that expressly leverage the ratings of different users additionally thereto of the target user, it in the main focusses on the target buyer's own scaling and also the attributes of the things that the buyer liked.
Beside these content-based ways, it alsohas some drawback also: It provides obvious recommendations thanks to the utilization of content or keywords. for instance: if a buyer hasn't used a product with explicit bunch of keywords, such a product can haven't any probability to being suggested. this is often thanks to the made model is restricted to the buyer at end, and also the neighborhood data from similarbuyers isn't leveraged. So,this technique reduces the variety of the suggested things, that is undesirable. This technique is effective in giving recommendation to the new products, they are not successful in providing recommendation to the new users. Reason behind it's going to be that the coaching model for the target buyer must make use of the history of their ratings and it is necessary to possess great deal of ratings obtainable for target user so as to form sturdy predictions while not over fitting. Therefore, this technique has completely divergent tradeoffs of cooperative filtering systems model. though the said description can give us the traditional learning-based system read of content-based ways, a wider read of those ways is typically used. Let's take an instance: buyer will specify applicable bunch of words in their profiles. These keywords are wanted to match with product descriptions so as to form recommendations for the same. Such associate is used in predictions. On the other end, the
The first supply of information may be a detail of varied things in measuresto content-centric attributes. For instance: the text details of associate product by the creator. Other supply of information may be a buyer's profile, that is formed from feedback of the user concerning numerous things. The feedbacks provided by the user may well be specific or specific. specific feedback could result in scaling, whereas constant feedbacks could result in user action. The scaling square measure gathered in such a fashion as that of cooperative system. The buyer profile co-relates the attributes of numerous things to buyer interests that is it's going to otherwise be ratings. For example: buyer profile may be a gaggle of labelled employment documents of the item details, the user scaling as a result of a classification or regression model and the labels, relating the item attributes to the user scaling. for the foremost half user profile depends on the methodology at hand. For example: specific ratings may perhaps be used in one of the settings, and particular feedback may be perhaps used in other one. it's realizable for the buyer to determine their own profile in terms of keywords of passion, and this approach also shares more or less characteristics with knowledge-based advised model. It permits recommendations in such the method that they'll take out the attributes from the freshly new things and this cold-start disadvantage for spanking new buyers can't be
system isn't delimited to solely net domains. Keywords Content-based systems have some basic parts, that stay provided in details of the merchandise square measure invariant across completely different instantiations of such want to produce recommendation in different e-commerce systems. As content-based work with a large kind of things settings. In different settings, relative attributes like price, description and data concerning users, thus one should manufacture and genre, could also be utilized in convert these differing kinds of unstructured knowledge additionality to keywords. this style of attributes square into standardized descriptions. In different cases, it's most measure wants to make structured representations, that can popular to convert the item descriptions into keywords. be hold on in electronic information service. In such cases, Hence, content-based system for the most part, however it's mendatory to mix the unstructured and structured not solely, operate within the text domain. Most of them attributes in a very single structured illustration. the square measure natural applications of content-based training technique within the structured domain have blunt systems also are text-centric. Generally, regression analogues within unstructured domain and contrariwise. modelling and text classification ways stay the foremost However, most of those ways is simply tailored to wide used methods for making content-based suggested structured settings. model The off-line parts square measure wants to make a in reference to the attributes of items. The learning model is condensed system, i.e., usually a regression model or designed on this work data. The generated model is then classification model. Now this copy is utilized for the net shown as a result of the user pro?le for which it relates user development of advice for buyer. the assorted parts of interests to item attributes content-based model square measure are as follows: Filtering and suggesting: during this step, the learned Pre-processing and eradication: Content-based model, unit model from the previous step is employed to form of measurement utilized during a massive reasonably recommendations on things for speci?c buyer. Necessary domain, like music choices, news, product details, web step is that it terribly e? cient a result of the predictions has pages, and so on. In many cases, choices unit of measurement eradicates from various sources to convert to be compelled to be performed in real time. them into a keyword-based vector-space illustration. Feature illustration and improvement method is especially Usually, this can be the ?rst step of any content-based necessary once the format is not structured is employed for recommendation system, and its very domain-speci?c. illustration. The feature eradication part is in a position to whereas, the correct eradication of the foremost see baggage of words from the unstructured details of informative choices is very important for the effective merchandise or net content. whereas, these presentations functioning of any content-based recommender system. have to be compelled to be cleansed and pictured in a very appropriate format for process. There square measure Content-based learning of user pro?les: A content-based model is different for each user. So, a different model for many steps within the improvement process: each user is created to identify the interests of user in each Stop-word removal: Description written by user can item bought, which is done by analyzing the item history contains words which are not specific to the item at hand. and the way a person rates the item. In attaining this goal, These words square measure is used more frequentlyfor we need feedback from user history. This feedback is used example, alphabetssuch as“the,” “a,” and “an” won't be significantly distinct to the product at hand. within the

recommended application, it's easy to find such words. Commonly word which are articles, noun, adjective, and pronouns square measure are used as stop-words. Stemming: In stemming, variations of a similar word square measure consolidated. For example, singular and plural varieties of a word or di? erent tenses of a similar word square measure consolidated. In some cases, common roots square measure extracted from numerous words. For example, words like “hoping” and “hope” square measure consolidated into the common root “hop.” after all, stemming will typically have a harmful e? ect, as a result of a word like “hop” contains a di? erent which means of its own. several o? -the-shelf tools square measure obtainable for stemming. Phrase extraction: the concept is to discover words that occur along in documents on a frequent basis. For example, a phrase like “hot dog” suggests that one thing di? erent from its constituent words. Manually de?ned dictionaries square measure obtainable for phrase extraction, though machine-controlled ways may be used. once execution these steps, the keywords square measure reborn into a vector-space illustration. every word is additionally brought up as a term. within the vector-space illustration, documents square measure pictured as baggage of words, along with their frequencies. though it would be tempting to use the raw frequency of word prevalence, this can be often not fascinating. This is a result of ordinarily occurring words square measure often statistically less discriminative. Therefore, such words square measure usually discounted by down-weighting. this is often the same as the principle of stop-words, except that it's drained a soft means by discounting the word, instead of utterly removing it. Gathering likes and dislikes from user Feature choice and weight feature is to make sure that solely informative words ought to retain within the vector area illustration. Most of the suggested systems expressly advocate the scale cut-off that ought to be utilized in the number of keywords. Basically, plan is that clamorous words usually end in overfitting and might be removed a priori. it's necessary, considering the actual fact that the number of documents obtainable to be told a specific user profile is usually not giant. If the number of documents obtainable for learning is a smaller amount than then tendency to overfit are larger. Therefore, it's necessary to cut back the scale of the feature area. There square measure 2 styles of options informativeness within the document illustration that are:
The measures for computing feature info is wont to perform a tough choice of options or to heuristically weight the options with a operate with a computed qualification. The measures used for feature informativeness square measure completely different, it depends whether or not the user rating is in numeric or categorical worth. For example: consistent with binary ratings (ratings with little values), here we are able to use categorical illustration instead of going towards numeric representations.
In this system, content-based ways are directly used for cooperative filtering models and content-based ways. It says that content-based ways are directly used for cooperative filtering. whether or not the content description of associate item refers to its descriptive keywords, it's doable envision eventualities, here the ratings of user's square measure leveraged to outline content-based descriptions. for every item, one will concatenate the user name (identifier) of a user World Health Organization has rated the item with this rating worth, we are able to produce a replacement “keyword”. Therefore, several things are classified in terms of varied moving picture as follows: Terminator: Ram#Like, Dean#Dislike, Sam#Like Aliens: Ram#Like, Peter#Dislike, Roy#Dislike, Peter#Like Gladiator: Ram#Like, Sam#Like, Dave#Like This “#” image here is to symbolize the putting in limit and guarantee a selected bunch of word for each user-scale combination. This method is simpler, once the amount of doable ratings is little (for example: single or binary ratings). once this kind of content-based details has been designed, it is used with associate off-the-peg 'content- based' formula. There should be 1 mapping in the ensuing ways and numerous cooperative filtering system, it's supported the tactic usageof classification. though every such method map to a cooperative filtering system, the converse isn't true, reason behind this is often several cooperative filtering ways cannot be captured by this technique.
weighting: it involves giving larger importance to about which customer bought which product and according to that, build an item to item affinity score, and then we use it for recommendation. This data files are saves in '.csv' format with having entries of each product and user buying the particular item. This is the data file: Step 1: The algorithm we are using here is the association rules mining algorithm, or more correctly called, marketbased analysis. Association rules mining are put rules that specify the dependency of one item onto another
Step 1: Dataset Now we will be going to implement the case for building recommendations. So, when a customer reaches site and ahs bought an item, we should recommend a person about other products also. So, for this, we are going to use data
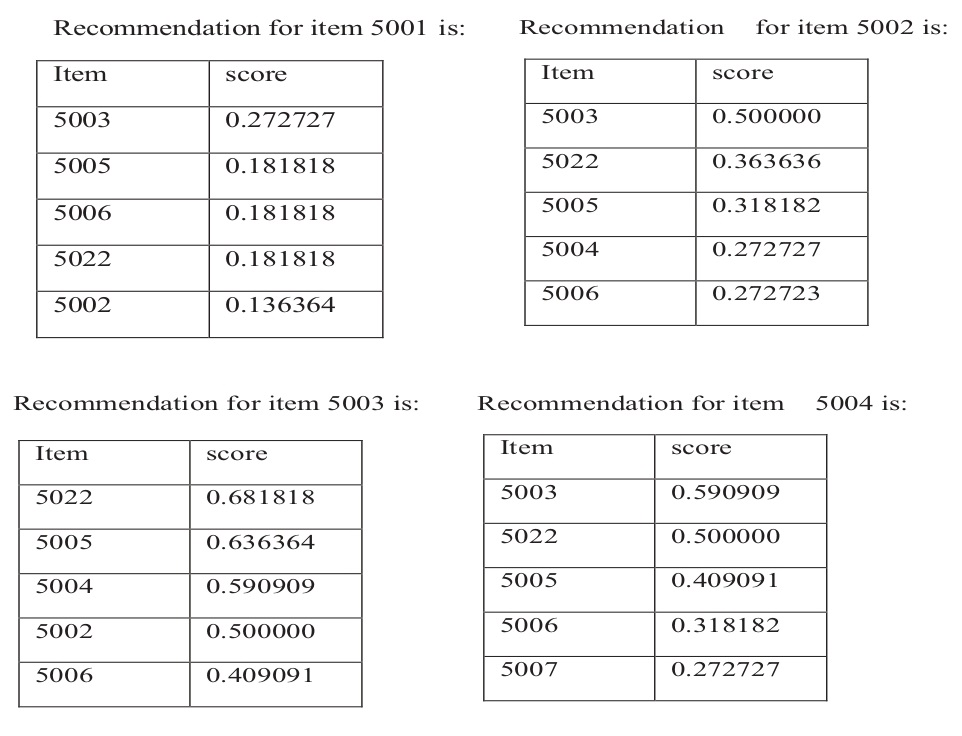
Step 2: code used: We are going to take every item and find the affinity of that particular item to other items. The more the number of customers who buy both the products, the higher is going to be affinity score. This is how affinity score could be calculated between each item. Step 3: Result Here we are taking the data where 27 customers have made the transaction of around 250. And hence according to this data we are find the recommendation for various product according to the need of the users. Recommendation for item 5001 is: Recommendation for item 5002 is:
coaching models square measure created for the systems have the advantage that they will handle cold begin suggested system. The content attributes in item issues with regard to new things, though they can't handle descriptions square measure combined with user ratings to cold-start issues with regard to new users. The fluke of form user pro?les. Classi?cation models square measure content-based systems is comparatively low as a result of created on the idea of those models. These models square content-based recommendations square measure measure then want to classify item descriptions that have as supported the content of the things antecedently rated by the user. Recommender systems open new opportunities of retrieving personalized info on the web. It conjointly helps to alleviate the matter of knowledge overload that may be a quite common development with information retrieval systems and allows users to possess access to merchandise and services that aren't pronto obtainable to users on the system.
Pu P, Chen L, Hu R. A user-centric evaluation framework for recommender systems. In: Proceedings of the fifth ACM conference on Recommender Systems (RecSys'11), A.M. Acilar, A. Arslan A collaborative filtering method based on Artificial Immune Network ACM, New York, NY, USA; 2011. L.S. Chen, F.H. Hsu, M.C. Chen, Y.C. Hsu Developing Hu R, Pu P. Potential acceptance issues of personality- ASED recommender systems. In: Proceedings of ACM recommender systems with the consideration of product profitability for sellers conference on recommender systems (RecSys'09), New M. Jalali, N. Mustapha, M. Sulaiman, A. Mamay York City, NY, USA; October 2009. WEBPUM: a web-based recommendation system to B. Pathak, R. Garfinkel, R. Gopal, R. Venkatesan, F. YinEmpirical analysis of the impact of recommender systems on sales Rashid AM, Albert I, Cosley D, Lam SK, McNee SM, Konstan JA et al. Getting to know you: learning new user preferences in recommender systems. In: Proceedings of the international conference on intelligent user interfaces; 2002. P. Resnick, H.R. Varian Recommender system's

